
Linear Models
Linear Regression
Linear Regression is a method used to model the relationship between a dependent variable and one or more independent variables by fitting a Linear Equation to the data. We basically try to find the best line (or plane or hyperplane depending on the dimensionality) that represents our data.
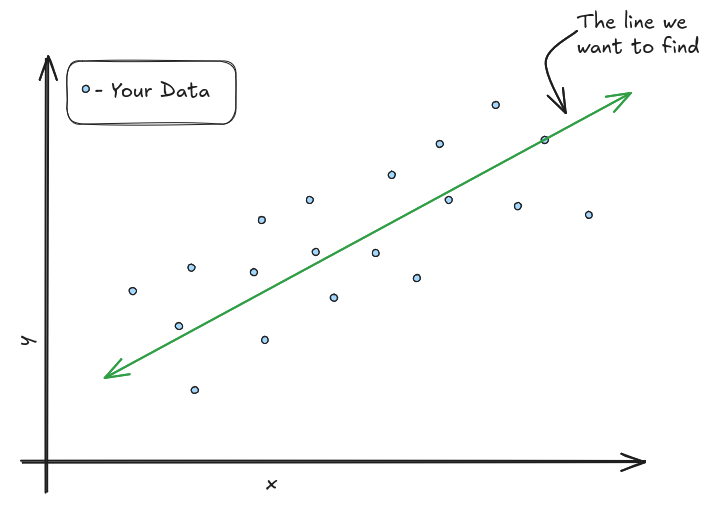
How Does it Work?
A linear equation with one independent variable (or feature) looks like this. \(Y = \theta_0 + \theta_1\cdot X\)
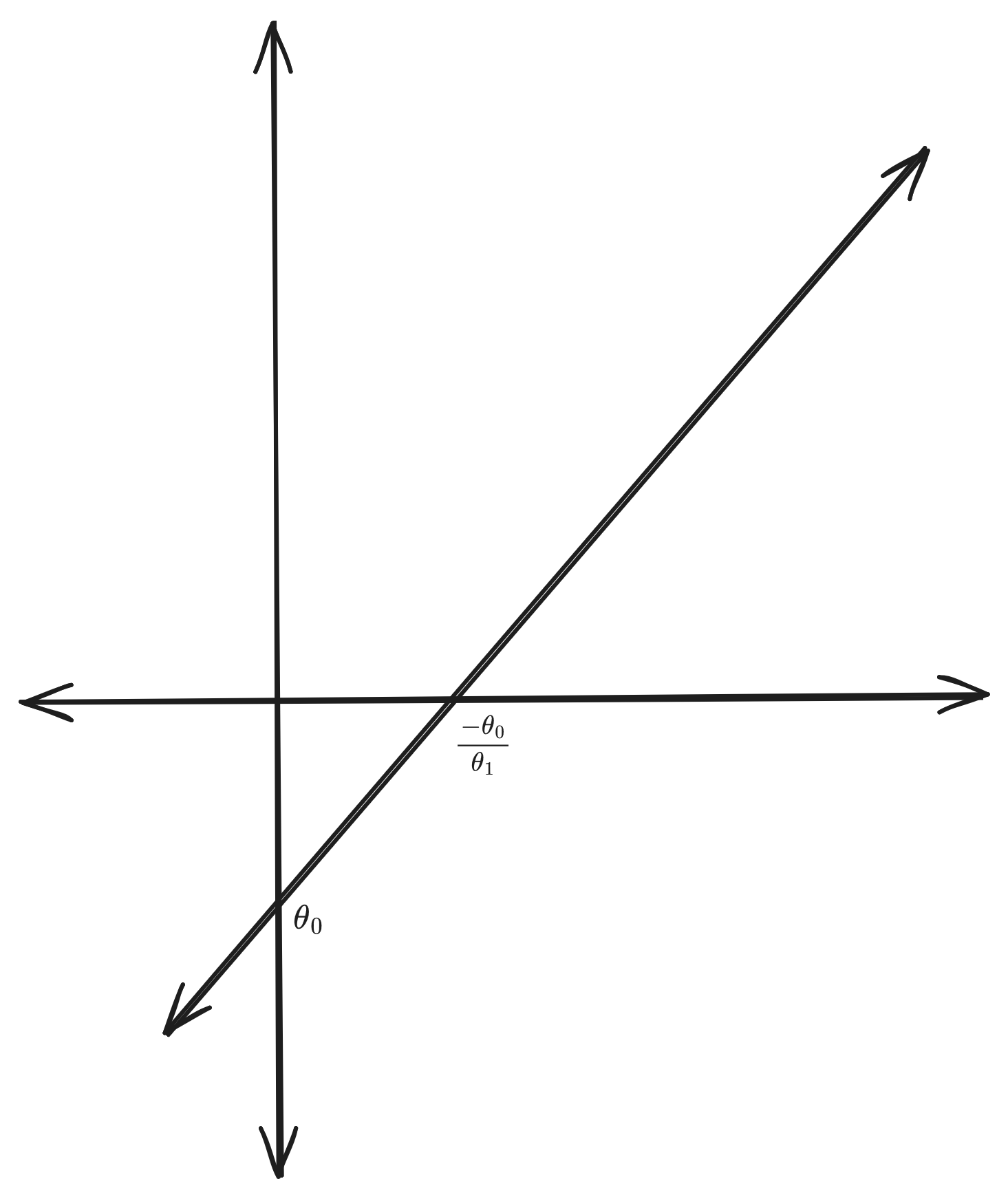
When you have more than one feature, it becomes
\[Y = \theta_0 +\theta_1 \cdot X_1 + \theta_2 \cdot X_2 + ...\]which can be simplified into
\[\sum_{j=0}^{n} \theta_j \cdot X_j\ \ \ \ \ \ where, X_0=1\\\]Also written as \(Y = h(X)\).
The above summation can be represented using matrices (for \(n=2\)) as
\[\theta = \begin{matrix} \theta_0 \\ \theta_1 \\ \theta_2 \\ \end{matrix}\ \ \ and\ \ \ X = \begin{matrix} X_0 \\ X_1 \\ X_2 \\ \end{matrix}\]\(\theta\) is called the parameters (or weights) of the learning algorithm. The objective of the learning algorithm is to choose parameters \(\theta\) that allows us to make good predictions for \(Y\), i.e., Choose \(\theta\) such that \(h(x) \approx y\) for training samples.
To achieve this, we need to minimize the difference between \(h(x)\) and \(Y\) in the training samples. This difference is called the loss (or cost) and for linear regression, it is defined using the Mean Square Error (MSE). So our goal is to minimize the loss by adjusting \(\theta\).
\[\underset{\theta}{minimize}\ \frac{1}{2}\sum_{i=1}^{m}J(\theta)\]where \(J(\theta) = (h_\theta(x^{(i)}) - y^{(i)})^2\), \(m\) is the number of training samples, and \(x^{(i)}\) and \(y^{(i)}\) are individual training samples.
The \(\frac{1}{2}\) is present just to make the gradient computation easier. When you differentiate the squared component, the \(\frac{1}{2}\) will get cancelled in the result
Optimizing using Gradient Descent
There are a lot of optimizers that can be used to minimize the cost function. In this case, let’s look at Gradient Descent.
For the cost function \(J(\theta)\) and model parameter \(\theta_j\), Gradient Descent is written as
\[\theta_j := \theta_j - \alpha\frac{\delta}{\delta\theta_j}J(\theta)\]where \(\alpha\) is the learning rate.
So, continuing with the computation of the new value for \(\theta_j\),
\[\frac{\delta}{\delta\theta_j} J(\theta) = \frac{\delta}{\delta\theta_j} \frac{1}{2}\sum_{i=1}^{m}(h_\theta(x^{(i)}) - y^{(i)})^2\]Ignoring the \(\Sigma\) and computing for a single training sample (for the sake of simplicity and the sum rule of differentiation),
\[= \frac{\delta}{\delta\theta_j} \frac{1}{2}(h_\theta(x) - y)^2\] \[= 2\cdot\frac{1}{2}(h_\theta(x)-y)\cdot\frac{\delta}{\delta\theta_j}(h_\theta(x)-y)\] \[= (h_\theta(x)-y)\cdot\frac{\delta}{\delta\theta_j}(\theta_0x_0+\theta_1x_1...+\theta_nx_n-y)\]None of the terms inside the partial derivative depend on \(\theta_j\) except for \(\theta_jx_j\). So the partial derivative of all these terms are \(0\) and for \(\theta_jx_j\), it is \(x_j\). Therefore, the above expression simplifies into
\[= (h_\theta(x)-y)\cdot x_j\]That gives us \(\theta_j := \theta_j - \alpha(h_\theta(x)-y)\cdot x_j\).
The above is for just one training sample. For the entire training set, we get
\[\theta_j := \theta_j - \alpha\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})\cdot x^{(i)}_j \ \ \ \ -\ Eq.\ 1\]and the derivative of the cost function when defined using all the training samples is
\[\frac{\delta}{\delta\theta_j} J(\theta) = \sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})\cdot x^{(i)}_j\]We’re including a \(\frac{1}{m}\) to avoid exploding gradients. When are add the gradients of all the training samples, the step size we take might increase with the size of the dataset. To avoid this, we’re averaging out the gradients using \(\frac{1}{m}\).
This is to optimize one parameter (which is used by one feature in the input matrix). So for a training sample with \(n\) features, Gradient descent becomes
for j = 0, 1, ..., n
Eq. 1
This operation is also called Batch Gradient Descent because we process the entire dataset for every step in the descent.
Performing the Gradient Descent multiple times will eventually minimize the cost and give us a \(\theta\) that would be best fitting linear equation that models/describes the training data.
Additional Info
- The cost function (MSE) is a quadratic function. This means it has exactly one minima (local and global minima are the same).
- For Linear Regression, you can find the optimal \(\theta\) (or global minima) in a single step using Normal Equations.